Key Takeaways
• The Event: AI-driven systems are no longer CPU-centric; workloads are fragmented across specialized processors.
• The Cause: Power density, latency, and data movement constraints force architectural specialization.
• The Implication: Wrong workload mapping increases BOM cost, power draw, and long-term supply risk.
🧠 Opening
For decades, the CPU defined system capability. Today, AI workloads, real-time perception, and data-intensive pipelines have fractured that model. CPUs, GPUs, NPUs, DPUs, VPUs, and newer accelerators now coexist in a single platform. This article clarifies who does what, and why these boundaries matter for OEMs, EMS providers, and hardware architects.
🔄 What’s Changing
AI is no longer a single workload. Training, inference, perception, networking, and control loops each stress different system limits. Power efficiency now outweighs raw compute in edge deployments, while data centers are constrained by bandwidth and offload efficiency. As a result, general-purpose processors are being relieved of tasks they were never optimized for.
📊 Data / Role Comparison
CPU: Optimized for control flow, branching logic, OS scheduling, and deterministic behavior.
GPU: Optimized for thousands of parallel threads and dense matrix math.
NPU: Optimized for fixed-function neural inference with tight power envelopes.
DPU: Optimized for packet movement, encryption, and storage I/O offload.
VPU: Optimized for image and video pipelines before AI inference even begins.
TPU / MaPU: Optimized for framework- or algorithm-specific acceleration.
QPU: Optimized for non-classical computation, outside commercial electronics cycles.
🧩 CPU — Central Processing Unit
Core Role: System control, orchestration, and decision logic.
Where it Fits: Industrial controllers, robot supervisors, server hosts.
Why It Still Matters: Every accelerator still depends on a CPU for coordination.
Representative Ecosystem: Intel, AMD, ARM.
⚡ GPU — Graphics Processing Unit
Core Role: Massive parallel computation.
Where it Fits: AI training, simulation, vision analytics.
Trade-off: Extreme throughput at high power and cooling cost.
Representative Ecosystem: NVIDIA.
🧠 NPU — Neural Processing Unit
Core Role: AI inference acceleration.
Where it Fits: Edge AI, smart cameras, mobile robots, AIoT.
Why It Exists: GPUs are inefficient for always-on inference.
Representative Ecosystem: Huawei, Google, Cambricon.
🔐 DPU — Data Processing Unit
Core Role: Data movement, networking, and security offload.
Where it Fits: Data centers, private clouds, industrial edge servers.
System Impact: Frees CPU cycles and reduces latency jitter.
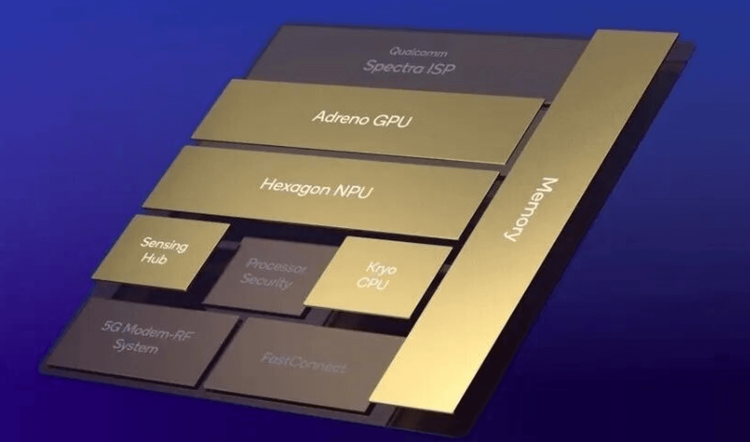
👁️ VPU — Vision Processing Unit
Core Role: Image and video processing before AI inference.
Where it Fits: Machine vision, video analytics, robot perception.
Why It Matters: Vision preprocessing can consume more power than inference itself.
Representative Ecosystem: Qualcomm.
🧮 TPU — Tensor Processing Unit
Core Role: Tensor-centric deep learning acceleration.
Where it Fits: Cloud AI and hyperscale training.
Constraint: High efficiency, low flexibility.
Representative Ecosystem: Google (internal deployment).
🧪 QPU — Quantum Processing Unit
Core Role: Quantum computation.
Where it Fits: Research, cryptography, materials science.
Reality Check: Not part of today’s OEM or EMS supply chains.
Representative Ecosystem: IBM.
🔧 MaPU — Machine Learning Processing Unit
Core Role: Flexible ML acceleration between GPU and NPU.
Where it Fits: Specialized AI workloads and domestic architectures.
Design Intent: Balance programmability and efficiency.
🚫 Why Old Assumptions No Longer Work
Assuming “CPU + GPU is enough” leads to thermal overload, wasted power, and inflated BOMs. Conversely, overusing fixed-function accelerators can lock systems into obsolete models. Modern systems require workload-aware partitioning.
📉 Implications for OEM / EMS / Procurement
• BOM Structure: More chips, but lower total system power.
• Supply Risk: AI accelerators have longer lead times than CPUs.
• Lifecycle Risk: AI models evolve faster than hardware refresh cycles.
• Integration Cost: Heterogeneous software stacks are now unavoidable.
🚀 How Smart Teams Are Responding
• Separating control, perception, inference, and data paths early in architecture design.
• Matching accelerator choice to deployment lifetime, not peak benchmark scores.
• Designing fallback paths when AI accelerators face allocation shortages.
• Treating power budget as a first-order requirement, not an afterthought.
🔚 Closing
The question is no longer “Which processor is the most powerful?” but “Which processor should do this job?” Teams that map workloads correctly gain efficiency, resilience, and long-term flexibility. The rest pay for unused silicon.
Soft CTA: Reach out to discuss workload-aware system partitioning and long-term AI hardware resilience.